
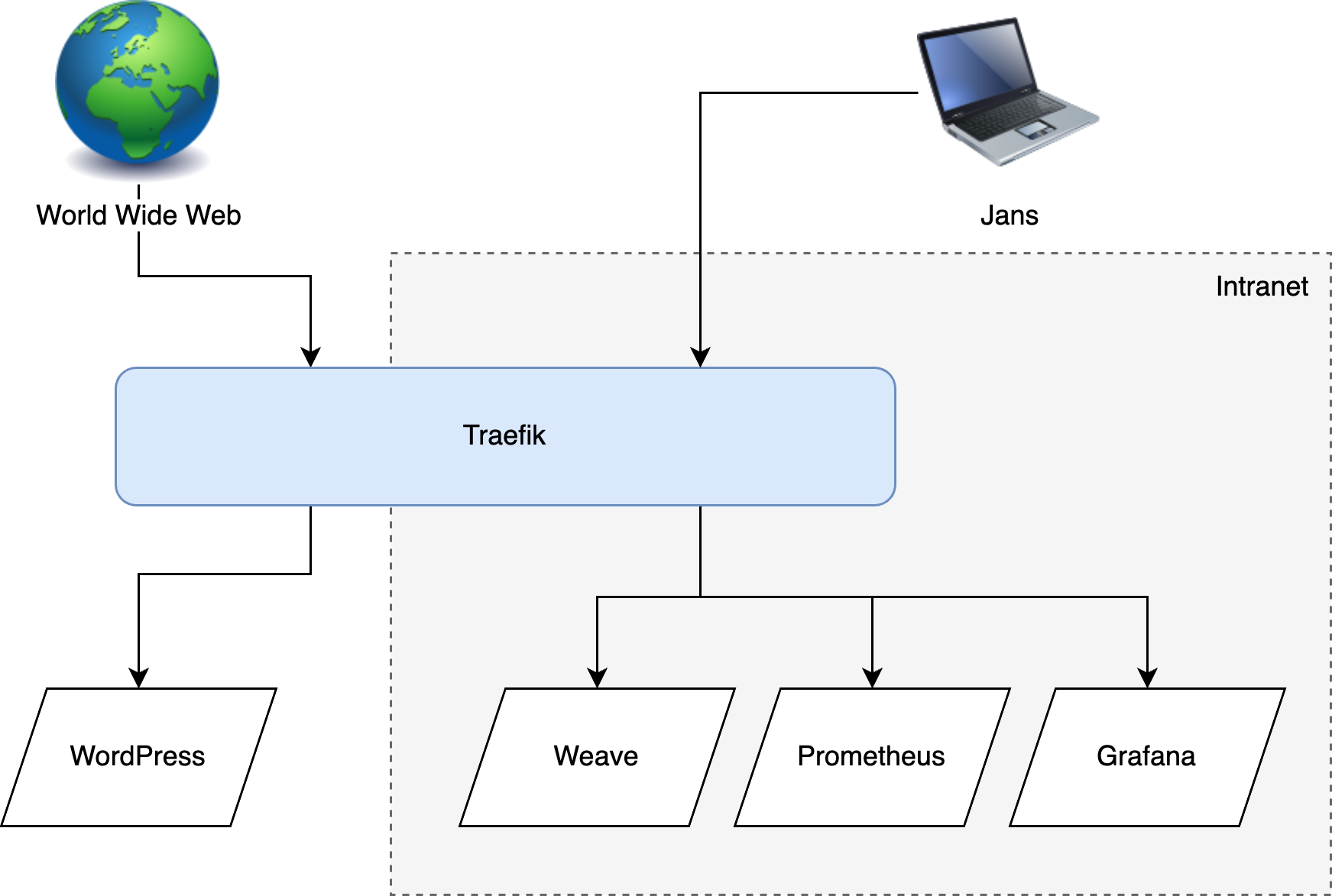
I recently started setting up a personal Kubernetes cluster, and along the way deployed quite a few services: Weave for gitops, Traefik for networking, Prometheus and Grafana for monitoring, and some other operations apps. The apps I just named all have frontends that are really useful, but I don't want to expose them to the world wide web. The solution to this problem is called an intranet: make a little internal network that can only be accessed by myself and then host all the apps on there.
As it turns out, configuring this is no joke. Here's my story:
The goal

Basically I want some of my Kubernetes apps to be exposed to the internet (eg a WordPress site) and some apps to only be accessible from my intranet (eg Weave and Grafana, which are purely operational apps meant for managing my infrastructure). The good news is that Traefik can do this kind of routing, but the bad news is that there are a LOT of additional moving parts needed to make this happen. Let's get to it.
I'm going to split up the requirements into a few sections:
- Network layer: how the world connects to the cluster, how the intranet clients connect to the cluster, and how the nodes in the cluster connect to each other.
- DNS: the public hostnames, the intranet hostnames, and the in-cluster service hostnames.
- Routing: how the cluster distinguishes between intranet and internet traffic.
- Certificates: public HTTPS and intranet HTTPS
A quick word on infrastructure
I don't love Oracle, but one thing I must concede is that they have a very generous free tier on their cloud platform. Depending on your CPU & RAM configuration, you can run up to 6 VMs for free forever. And you can run pretty much anything you want on those VMs. In my case, I'm running a Kubernetes cluster on 3 nodes across two datacentres, plus a dedicated VPN server. All for free. Pretty good deal.
Network layer
This is the simplest setup I could think of: my cluster runs on 3 nodes, and to get private intranet access, I got a dedicated VM running OpenVPN on the same subnet as the cluster. I could probably have tried running OpenVPN inside the cluster, but Oracle had a pre-baked OpenVPN image ready to go, and I was looking for minimal hassle.

Oracle automatically assigns each node in a public subnet a public IP address. For my use case I only needed two of the nodes public - OpenVPN, and one of the cluster nodes.
The VPN setup
The OpenVPN use case is pretty clear: I can use my personal computer to connect to the VPN server (which is publicly hosted), which will then effectively put my device on the same internal network as the VPN. There's a tonne of security built in to OpenVPN so I have no worries that any unauthorised users will get in to the network this way. For sake of interest, here are my OpenVPN routing settings:

The cluster setup
My 3 nodes are running k3s, which is a super easy-to-setup, yet production-ready Kubernetes implementation. They all communicate with each other on a variety of ports, and the security group rules allow all traffic to all ports inside the subnet.
Now for the internet to access the cluster I decided to go the extremely simple route of using a NodePort service and having Node 1 accept all inbound traffic. If you don't know, a NodePort service in Kubernetes is a way of accepting network traffic by opening a specific port (say port 80) on all nodes, and then using black magic to forward traffic from that port to the target pod in the cluster (whatever node it may be on). So in my case, traffic would come directly to Node 1 port 80, and it would then forward the request to the WordPress pod running on node 3, for example.
Why not use a Load Balancer? A load balancer is the most production-y way of doing Kubernetes ingress, but there are a few reasons I didn't end up going that route:
- I tried getting the LB service to spawn an Oracle LB, but it didn't work.
- I tried manually setting up an Oracle LB, but that also didn't work.
- At the end of the day, a dumb round-robin LB won't really help much since for any given node, the chances are 66% that the destination pod is NOT on the current node and so the traffic will have to be forwarded anyway.
- I'm not running any crucial HA workloads on my cluster.
DNS
So how did I set up hostnames for all these nodes? The easiest of course were the public IPs:
vpn.example.org-> VPN public IPexample.org-> Node1 public IP*.example.org-> CNAME example.org
So now I can connect to my VPN with the address vpn.example.org, and I can connect to my cluster using example.org, or any subdomain (except for vpn.)
What ended up being much trickier is the intranet DNS setup:

Let's walk through the internal use cases:
Internal VPN clients
A device on the VPN must be able to resolve the intranet domain (eg grafana.good.vibes) to Node 1, where the main NodePort inlet is. To achieve this, I'm running a small instance of dnsmasq directly on Node 2. Dnsmasq is a lightweight DNS server that's easy to install and set up. It has to run on one of the nodes so that I can use that node's IP address as the canon DNS server for the intranet. Here's my dnsmasq config (/etc/dnsmasq.conf)
# Never forward plain names (without a dot or domain part)
domain-needed
# Never forward addresses in the non-routed address spaces.
bogus-priv
# Listen addresses to bind to (localhost and subnet IP)
listen-address=127.0.0.1
listen-address=10.0.0.109
bind-interfaces
# Update hosts file
expand-hosts
# Add domains which you want to force to an IP address here.
address=/good.vibes/10.0.0.62
# This will resolve anything.good.vibes to 10.0.0.62 (which is the Node 1 IP, where the main inlet is)Now we need to tell VPN clients to use Node 2 as the intranet DNS server. Luckily this can be configured with the OpenVPN frontend:

10.0.0.109 is the private IP of Node 2 (where dnsmasq is running), and 169.254.169.254 is Oracle's internal DNS server (used as a fallback for dnsmasq). The DNS zones setting tells OpenVPN which domains to route into the intranet, as opposed to the internet.
Pods in the cluster
Now that VPN clients can look up grafana.good.vibes, we also need pods running in the cluster to be able to do the same. The default in-cluster DNS server with k3s is coreDNS. Luckily coreDNS can be configured quite easily in the k3s context, by simply creating a ConfigMap with whatever additional coreDNS config you want. K3S will automatically mount it in to the coreDNS pod for you, which is amazing. Here's my custom coreDNS config:
apiVersion: v1
kind: ConfigMap
metadata:
# This config is auto-mounted into the coreDNS pod
name: coredns-custom
namespace: kube-system
data:
goodvibes.server: |
good.vibes:53 {
errors
log
prometheus :9153
forward . 10.0.0.109
cache 30
}Some of the config is optional, but the important parts are:
- name and namespace - must be exactly
coredns-customandkube-systemfor k3s. goodvibes.server- this is the filename to be mounted into the coreDNS pod. Must end in.server.good.vibes:53- The first part is the domain to catch (anything.good.vibes), and the second part is the port to listen on. 53 is the default DNS port.forward . 10.0.0.109- forward DNS lookup requests to 10.0.0.109 (Node 2, where dnsmasq is).
Once you've applied the config to your cluster and restarted the coreDNS pod, the pods in the cluster should now be able to look up arbitrary hosts on the intranet! How exciting.
Routing
So where are we? We have a cluster with the main NodePort inlet on Node 1, receiving traffic both from the internet and the intranet on the same port: 80 (we'll talk about HTTPS in the next section). Now we need to make a plan to route all this incoming traffic to the right places. Essentially I want to specify a hostname per k8s-service, and then have traffic go the right place based on the requested host.

The default ingress controller that comes with k3s is Traefik, and boy is that a powerful piece of technology. Conveniently, k3s already has some default config for traefik set up from the get-go (eg listen on port 80, all the custom Kubernetes resources (CRDs), and so on).
Setting up routing is as simple as defining an IngressRoute manifest per host you want to route. For example, here's the manifest for routing grafana.good.vibes to the grafana service:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: grafana-ing
namespace: prometheus
spec:
entryPoints:
- web # port 80
routes:
- match: Host(`grafana.good.vibes`)
kind: Rule
services:
- kind: Service
name: prometheus-stack-grafana
port: 80The service prometheus-stack-grafana is automatically created when you deploy the kube-prometheus-stack helm chart. But that service name can be literally any k8s service you want.
And that really is it as far as routing goes. Just throw down as many IngressRoutes as you want and traefik will take care of routing inbound traffic to the right service.
SSL certs
Of all the sysadmin I did to get my intranet up and running, HTTPS was by far the hardest part to set up. However, after having figured it out I'm incredibly grateful for the learnings that came from it, and proud of myself for getting this complex infrastructure scenario working. But enough babble, let's get to it:

Let's go over the easy part first: public HTTPS with Let's Encrypt. If you don't know, LE is an awesome nonprofit organisation that provides free SSL certificates to pretty much any webserver that requests it. According to their website, they secure over 300 million sites. Configuring Traefik to request certs from LE is pretty easy. Here's a simplified version of my traefik config (note that it's in a manifest because that's the way k3s recommends you configure traefik):
# /var/lib/rancher/k3s/server/manifests/traefik-config.yaml
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: traefik
namespace: kube-system
spec:
valuesContent: |-
certResolvers:
letsencrypt-staging:
email: me@example.org
storage: /data/acme-letsencrypt-staging.json
caserver: "https://acme-staging-v02.api.letsencrypt.org/directory"
tlschallenge: true
logs:
general:
level: "DEBUG"
ports:
web:
redirectTo: websecureWhat's going on here?
- I've configured a certificate resolver called
letsencrypt-staging, which uses LE's staging (aka preprod) environment to fetch certs. The certs retrieved from this endpoint are not signed by the normal LE root Certificate Authority, but instead by a staging CA called Pretend Pear X1. If you install that CA onto your PC your browser won't complain about the staging cert being insecure.- I strongly recommend you use LE's staging environment while setting up Traefik. I originally went straight to their production environment and quickly got banned for requesting too many certs. While I was setting up my intranet CA (coming up next) I had to restart traefik a lot, and also had to clear the certificate data to force traefik to request new certs. Turns out LE doesn't like so many cert requests, and now for the next few months I have to serve Pretend Pear certs on some of my public websites ????.
- The
tlschallengeis the easiest one to set up for both the intra- and internet use cases. You can read up on it here, but basically LE goes and chats to traefik on port 443 using a custom protocol called TLS-APLN-01. Traefik knows how to interpret this protocol and respond to the challenge, effectively confirming that it is the requestor of the cert and host of the target domain. - I recommend setting the log level to
DEBUG- it helps a lot with figuring out this cert stuff. - The
redirectTothing is just a shorthand way of telling Traefik to respond to all port 80 requests with a 308 redirect to the same URL but with https as the scheme. This lets clients connect to port 80 and immediately get upgraded to an HTTPS connection.webandwebsecureare predefined entrypoints equivalent to port 80 and 443 respectively.
And now you just need to edit your public IngressRoutes to use the cert resolver, and change the entrypoint to websecure.
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: blog-ing
namespace: wordpress
spec:
entryPoints:
- websecure
routes:
- match: Host(`blog.example.org`)
kind: Rule
services:
- kind: Service
name: wordpress
port: 80
tls:
certResolver: letsencrypt-stagingAnd Bob's your uncle. Now if you go to https://blog.example.org you should see content being served over HTTPS with a cert that looks something like this:

I just noticed LE has multiple staging CA's (Artificial Apricot ????), but rest assured if you have the Pretend Pear CA trusted, all of them will be trusted. Just don't forget to switch over to the production endpoint when you're confident your traefik setup is stable.
Intranet HTTPS
Okay, now for the juicy stuff: getting HTTPS working inside an intranet. The biggest obstacle here is that by design all the intranet endpoints (eg grafana.good.vibes) are inside the intranet and are not accessible from the public internet. This means we can't use LE to get certs.
The way to make HTTPS happen in your intranet is by using a self-hosted CA. Step-CA is exactly this: a self-hostable certificate authority that can handle cert requests and validate challenges such as the TLS-ALPN-01 challenge. Cool! Let's set it up.
The easiest way to get Step-CA working in a cluster is by following their guide here, which explains how to set up good default config and deploy their helm chart. I've abridged my values here:
inject:
certificates:
intermediate_ca: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
root_ca: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
config:
files:
ca.json:
address: :9000
authority:
provisioners:
- name: acme
type: ACME
- encryptedKey: ey...Tg
key:
alg: ES256
use: sig
...
name: jwk
type: JWK
dnsNames:
- step-certificates.smallstep.svc.cluster.local
secrets:
ca_password: ...
provisioner_password: ...There were only two things I had to change:
- Under
provisionersI had to add an item calledacmewith typeACME. You need at least oneACMEprovisioner configured, but you can call it whatever you want. It will end up in a URL later on, so remember what you set it to. - Under
dnsNamesprovide a list of hostnames that Step will be serving on. The one ending incluster.localis the default fully-qualified domain name of the Step-CA service created during the helm deployment. That's the one Traefik will use to contact Step to request certs. - Be sure to save your CA and provisioner passwords somewhere secure. You'll need them to make changes to the Step configuration.
Okay now let's wire up traefik. Add smallstep to your traefik config:
# /var/lib/rancher/k3s/server/manifests/traefik-config.yaml
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: traefik
namespace: kube-system
spec:
valuesContent: |-
certResolvers:
smallstep:
email: me@example.org
storage: /data/acme-smallstep.json
caserver: "https://step-certificates.smallstep.svc.cluster.local/acme/acme/directory"
certificatesDuration: 24
tlschallenge: true
letsencrypt-staging:
...Take note:
- The email address must be exactly the same for all cert resolvers. Don't ask me why. Some limitation traefik imposes.
- The ca server URL includes
acmetwice. The first one is the resource name, and the second one is the provisioner name (we set earlier in the Step chart values). - By default Step certs last 24 hours and need to be renewed every day. I thought traefik was clever enough to check cert expiry dates and self-determine when to renew them, but I was wrong. You need to specify explicitly how often traefik should renew certs, which is what the
certificatesDurationproperty is for. Btw the default for this property is 2160 hours (90 days), which happens to be the duration of time LE certs are valid for.
Cool so now we have step configured as a cert resolver. Good to go? Afraid not. Step can only issue certs over HTTPS, and the cert that Step serves is signed by the root CA cert we set in the chart values earlier. That's cool, but the problem is that traefik doesn't recognise that CA, and so it will fail to make cert requests.
To solve this problem we need to make traefik trust the step root CA. The cert content is stored in a ConfigMap called step-certificates-certs in whatever namespace you installed step onto. In order to mount the cert into Traefik, you need to copy the ConfigMap to the traefik namespace (which is kube-system by default for k3s) and then mount it by using this (very non-standard) mount config:
# /var/lib/rancher/k3s/server/manifests/traefik-config.yaml
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: traefik
namespace: kube-system
spec:
valuesContent: |-
certResolvers:
...
volumes:
- name: step-certificates-certs
type: configMap
mountPath: /certs
ports:
...Grand, so now we have the Step root CA cert mounted in /certs/root_ca.crt, but how do we make traefik trust it? (Skip to the last approach for the correct answer)
First approach: ServersTransport
Traefik has a CLI option called --serverstransport.rootcas, which allows you to define a list of root CAs traefik should trust when communicating with backends (eg pods that traefik is reverse-proxying for). So that's what I configured first:
spec:
valuesContent: |
additionalArguments:
- "--serverstransport.rootcas=/certs/root_ca.crt"Yeah turns out that doesn't work for cert resolvers, only for backend servers. ☹️
Second approach: Make Step a backend
Okay so custom CA certs work for backends, so why not make Step-CA a backend? We can then serve Step through plain HTTP. Something like this:

I'll save you all the config this took to set up, because it actually doesn't work. To be clear, the local port with custom CA cert does work, and you can configure a CA server with plain http in Traefik, but somewhere in the Traefik codebase https is hardcoded and enforced for some (but annoyingly not all) requests to the CA server. So even with http://localhost:1234 configured as the CA server, traefik still tries to request certs from https://localhost:1234. On to the next approach.
Third approach: the Linux-y way
The normal way of trusting custom CAs in linux is by copying the cert to /usr/local/share/ca-certificates/ and then running update-ca-certificates, which then does some magic to update system cert store hashes and thus allows all programs on the system to verify certs signed with the newly installed CA.
The traefik chart doesn't let you override the entrypoint, but it does let you specify a postStart lifecycle hook, which effectively lets you run arbitrary commands inside the pod when it starts up. Here's what I set up:
spec:
valuesContent: |
deployment:
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "cp /certs/root_ca.crt /usr/local/share/ca-certificates/ && update-ca-certificates"]This does work insofar as it updates the trusted certs correctly, but unfortunately it's just too late. By the time the CA is trusted, traefik has already initialised and attempted to request certs. As it happens if traefik fails to get certs at boot-time, it doesn't retry. Ever... So much for this approach.
Fourth approach: LEGO
I found this smallstep guide online that says you need to set an environment variable called LEGO_CA_CERTIFICATES to have traefik trust custom CA certs for cert resolvers. It was a pretty random suggestion, but I was out of ideas so I added the following environment variable:
spec:
valuesContent: |
env:
- name: "LEGO_CA_CERTIFICATES"
value: "/certs/root_ca.crt"This env var isn't documented anywhere on Traefik's docs, but lo and behold it works! Sort of... With this env set, traefik is able to successfully request certs from Step-CA, but only from Step-CA. When communicating with Let's Encrypt, it fails with an error about an untrusted cert. Clearly, this env var makes Traefik only trust the specified list of certs, which is not what we want.
After some further searching about, I found where this env var is used: a Golang library called lego. It's basically a Let's Encrypt ACME client, but it works for any acme server, and Traefik obviously uses it to do certificate resolution. Wild. Some web searching later I found a PR that added a new feature to lego that lets you also trust the system certs (beyond just the listed CA certs). Here's the second env var we need:
spec:
valuesContent: |
env:
- name: "LEGO_CA_CERTIFICATES"
value: "/certs/root_ca.crt"
- name: "LEGO_CA_SYSTEM_CERT_POOL"
value: "true"And that's it! Now traefik can request certs from Step-CA and do SSL using the specified root CA cert, plus it can request certs from LE and do SSL using the system certs. Amazing. Here's what an intranet IngressRoute looks like with HTTPS:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: grafana-ing
namespace: prometheus
spec:
entryPoints:
- websecure
routes:
- match: Host(`grafana.good.vibes`)
kind: Rule
services:
- kind: Service
name: prometheus-stack-grafana
port: 80
tls:
certResolver: smallstepWhat a mission.